KuiperInfer (自制深度学习推理框架)学习记录
KuiperInfer (自制深度学习推理框架)学习记录
本系列文章是对KuiperInfer (自制深度学习推理框架)项目学习的记录。
第一节课
启动docker:
1 | |
第二节课-张量(Tensor)的设计与实现
[!TIP] 思考题
请你在此暂停阅读,写出你自己对张量类设计的思考,需要有那些数据成员和方法(比如一个张量需要被创建,且能够支持形状的获取),并在课程结束后对比自己的设计和本文的设计,看看区别在哪。
答:数据类型、数据维度、数据排布格式。张量类中定义了多个类方法,如返回张量的宽度、高度、填充数据和张量变形 (reshape)等操作。
[!TIP] 思考题
请你运行
test_create_tensor.cpp中对应的所有单元测试,观察张量创建的情况和不同方法获取的结果。(如果有不认识的方法不用担心,接下来马上会介绍。) 我们强烈建议你调试课件中提及的所有单元测试,并仔细观察数据的逐步变化,更欢迎你自己编写单元测试对其他方法进行熟悉。
[!TIP] .vscode配置
在 VS Code 中使用 Ctrl+Shift+P打开命令面板,输入Preferences: Open User Settings或Preferences: Open Workspace Settings。
第二节课
代码模板有个问题,在tensor.cpp中,Reshape函数中的const uint32_t current_size = std::accumulate(shapes.begin(), shapes.end(), 1, std::multiplies()); 会出现argument list for class template "std::multiplies" is missing的错误。这是因为,在 C++17 及更高版本中,std::multiplies 的默认模板参数被删除了,因此你需要显式地提供模板参数。 将其修改为:`const uint32_t current_size = std::accumulate(shapes.begin(), shapes.end(), 1, std::multiplies
作业1补充代码:
1 | |
Reshape函数:
1 | |
Fill函数:
1 | |
解释:armadillo库默认矩阵是按列优先存储的,所以如果要按照行优先填充,应该针对每个channel,将原矩阵每个channel的转置赋值给它,即channel_data = channel_data_t.t();。如果是列优先,直接复制即可,即std::copy(values.begin(), values.end(), this->data_.memptr());。
第三节课
胶水算子
[!NOTE]胶水算子是什么?
胶水算子(Glue Operator)是深度学习领域的一个概念,主要用于将不同的神经网络模块连接在一起。在模型构建过程中,尤其是在涉及多分支结构或需要整合不同特征的网络中,胶水算子扮演着非常重要的角色。胶水算子的作用
胶水算子通常用于以下几种场景:
- 连接不同维度的张量:在神经网络中,不同的分支可能会产生不同维度的张量。为了将这些张量合并或进行进一步操作,胶水算子可以对这些张量进行拼接(concatenate)或其他操作,使得它们可以正确地被后续的层处理。
- 融合多种特征:在处理多模态数据或多种特征时,胶水算子可以将这些不同来源的特征进行融合。常见的融合操作包括加法、拼接、平均、乘法等。
- 调整数据格式或形状:在某些情况下,数据的形状或格式可能不匹配,这时候胶水算子可以通过变换或重新排列数据的形状,使得数据能够被后续层顺利处理。
常见的胶水算子
以下是一些在深度学习中常见的胶水算子:
- 拼接(Concatenation):将多个张量沿着某一维度进行拼接,例如在特征维度上拼接来自不同卷积核的特征图。
- 加法(Addition):将多个张量逐元素相加,这种方式通常用于残差网络(ResNet)中的跳跃连接。
- 乘法(Multiplication):逐元素相乘,用于特征增强或门控机制。
- 平均(Averaging):对多个张量进行逐元素平均,用于融合多种特征。
- 堆叠(Stacking):类似于拼接,但一般是在新增维度上堆叠多个张量,形成一个新的高维张量。
胶水算子的应用场景
- 多分支神经网络:在像Inception模块或ResNet等结构中,胶水算子被广泛使用,用于整合来自不同分支的特征。
- 特征融合:在处理图像、文本、音频等多模态数据时,胶水算子可以帮助融合这些不同模态的特征,构建更强大的模型。
- 注意力机制:在一些注意力机制(如自注意力机制)中,胶水算子可以用于整合来自不同位置或不同头部的注意力结果。
总结
胶水算子在神经网络中扮演着连接和融合的角色,帮助不同的网络模块协同工作,从而实现更复杂的特征提取和处理。它的使用可以大大增强模型的灵活性和表现力。
LayerNorm
BatchNorm是把不同样本的同一通道做标准化,它保留了不同样本之间同一通道的差异,但抹去了同一样本不同通道的差距,适用于CV。
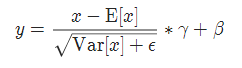
LayerNorm是把同一样本的不同通道做标准化,它保留了同一样本内不同通道的差异,抹去了不同样本之间差异,适用于NLP。
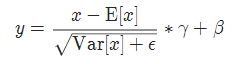
视觉的特征是客观存在的特征,而语义特征更多是由上下文语义决定的一种统计特征,因此他们的标准化方法也会有所不同。
ncnn是腾讯优图推出的在手机端极致优化的高性能神经网络前向计架框架,适用于手机端的CPU计算且无需依赖第三方计算库,ncnn只用作推理而非边训练边推理。
算子融合
在不进行算子融合的情况下,卷积层和批归一化层是依次执行的两个独立操作,这意味着需要分别计算卷积的输出,再将输出传递给批归一化层进行标准化,这样会涉及中间结果的存储和额外的计算。
算子融合的基本思路是将批归一化的计算直接嵌入到卷积计算中,从而减少中间计算和数据传输。
第五节课
单例模式
单例大约有两种实现方法:懒汉与饿汉。
- 懒汉:看名字就知道,不到万不得已就不会去实例化类,也就是说在第一次用到类实例的时候才会去实例化,所以上边的经典方法被归为懒汉实现;
- 饿汉:饿了肯定要饥不择食。所以在单例类定义的时候就进行实例化。
特点与选择:
- 由于要进行线程同步,所以在访问量比较大,或者可能访问的线程比较多时,采用饿汉实现,可以实现更好的性能。这是以空间换时间。
- 在访问量较小时,采用懒汉实现。这是以时间换空间。
“Magic Static” 是 C++11 标准中引入的一个特性,它指的是在函数内部定义的静态变量(包括局部静态变量)。这种变量只会在第一次执行该函数时被初始化,而且这种初始化是线程安全的。即使多个线程同时第一次调用该函数,静态变量也只会被初始化一次,并且在初始化完成前,其他线程会被阻塞,等待初始化完成后再访问该变量。
这个特性常用于实现单例模式(Singleton Pattern)或类似需要懒初始化的场景。相比于传统的双重检查锁定,使用“Magic Static”可以简化代码,同时确保线程安全。例如,实现一个单例类时,可以在一个静态成员函数中定义一个静态局部变量,这个变量就是单例实例,当多个线程同时尝试获取该实例时,C++11 标准保证了只有一个线程会进行初始化,其他线程会等待,直到实例被初始化完成。